发表于: 2019-08-29 23:17:06
1 716
今天完成的事情:
1、完成深度思考、脑图、任务总结
1.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么?
设计后台产品有句口诀:“展示列表优,编辑弹窗佳,筛选下拉好,组合查询棒”说的就是后台产品设计的小技巧。
这样设计是产品的设计理念应该更加符合用户的体验。
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
Redis 集群是一个可以在多个 Redis 节点之间进行数据共享的设施。把多个redis实例整合在一起,形成一个集群,也就是将数据分散到集群的多台机器上。当数据量过大一个主机放不下的时候,就需要对数据进行分区,将key按照一定的规则进行计算,并将key对应的value分配到指定的Redis实例上,这样的模式简称Redis集群。
redis三种缓存策略-主从复制,主数据库可以支持读写,而从数据库只能读,
redis三种缓存策略-哨兵 当一个人主数据库失效的时候,缓存哨兵模式会将一个从数据表变成一个人主数据库进行操作
redis三种缓存策略-集群 集群的分片特征在于将键空间分拆了16384个槽位,每一个节点负责其中一些槽位
3.什么是压测,为什么要进行压力测试?JMETER工具的使用
压力测试是模拟程序的真实运行情况,对某些高并发情况的测试,使用压力测试可以提前获取特定并发量时程序的效率吞吐量TPS等数据,可以提前做预防
JMter主要结合badboy一块使用,首先使用badboy进行录制然后导出成文件形式,在Jmter中打开 在监听器中添加需要测试的数据测试工具以及线程循环
4.Memcache和Redis可否做集群?什么样的情况下应该做集群?
可以
当数据量比较大时
5.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理?
脏数据:从目标中取出的数据已经过期、错误或者没有意义,这种数据就叫做脏数据。
可能
通过redis
if(redis存在数据){
读取redis数据
}else{
数据库读取,同时存redis+设置超时时间
更新部分:
if(数据库update){
更新redis+设置超时时间
6.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的?
应该先DB再缓存
要不然就会造成数据的延时性
7.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存?
区别在于JVM缓存属于共享缓存
Memcache属于独立缓存
不可以
因为不同的缓存机制的储存原理以及储存量不一样
在适合的场景应该选择合适的缓存方式
8.缓存应该在Service里,还是应该存放在Controller里,为什么?
应该放在controller里
在service中执行的是事务,(插入、更新、删除)出现错误可以回滚。只有查询可以放在controller,不过最好也放在service。
9.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情?
什么是缓存穿透?
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。如果key对应的value是一定不存在的,并且对该key并发请求量很大,就会对后端系统造成很大的压力。这就叫做缓存穿透。
关键词:缓存value为空;并发量很大去访问DB。
如何避免?
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
10.什么叫命中率?正常来讲,命中率应该控制在多少?
命中:可以直接通过缓存获取到需要的数据。
不命中:无法直接通过缓存获取到想要的数据,需要再次查询数据库或者执行其它的操作。原因可能是由于缓存中根本不存在,或者缓存已经过期。
通常来讲,缓存的命中率越高则表示使用缓存的收益越高,应用的性能越好(响应时间越短、吞吐量越高),抗并发的能力越强。
安装cpu的标准(1+80%)*(1+80%)以上
11.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些?
经常使用或者经常被访问的或者最近被使用的
NRU(Not recently used)
1、算法思想
NRU算法的思想是保留最近使用过的对象。
2、工作原理
缓存维护两个标记位,初始值为0。一个标记位R标识对象是否被使用过,另一个M用来标识对象是否被修改过。当一个对象在缓存中找到时,R置为1(referenced);当一个对象被修改时,M置为1(modified)。一个对象拥有的标记位有4种状态:
3. referenced, modified
2. referenced, not modified
1. not referenced, modified
0. not referenced, not modified
当缓存已满,但新的对象需要加入缓存时,从等级(上面状态最左边的数字代表等级)最低的对象中随机淘汰一个。
同时,缓存还有一个周期性的时钟,它在每个时间间隔会把所有对象的R标记为清零(这样就知道该对象最近,也就是一个时间间隔,是否被使用),但M不会清零。所以上面not referenced, modified状态看似不可能,但在经历过一个时间间隔,R位被清零时将有可能发生。
注意,该算法认为,最近被使用过的对象,比最近被修改过的对象更重要。
FIFO(First-in, first-out)
1、算法思想
该算法是最简单的缓存淘汰算法,其原理正如它名字一样,最近使用过的对象放到缓存队列的末尾,队列头部保存的是最早使用的对象。
LRU(Least recently Used)
1、算法思想
LRU算法的核心思想是基于“如果数据最近被访问过,它在未来也极有可能访问过”。因此如果数据的变化趋势符合这个思想,效果会比较好。
2、工作原理
(1)数据结构:链表,用于保存需要缓存的数据;HashMap,用来读取缓存中的数据,保证时间复杂读为O(1)
(2)实现:
当数据读取时,有两种情况:
a、数据在缓存中,则把该数据从新移到链表头部
b、数据不在缓存中,则把数据插入到链表中。
如何插入:
a、如果链表不满,则把数据插入链表头部
b、如果链表满了,则把尾部的数据删除,同时把其插入链表头部
12.什么叫一致性哈希,通常用来解决什么问题?
一致性哈希算法在1997年由麻省理工学院提出(参见扩展阅读[1]),设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
一致性哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/N 个关键字重新映射,其中K是关键字的数量,N是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
13.缓存的失效策略有哪几种,分别适合什么场景?
FIFO:First In First Out,先进先出。
- 判断被存储的时间,离目前最远的数据优先被淘汰。
LRU:Least Recently Used,最近最少使用。
- 判断最近被使用的时间,目前最远的数据优先被淘汰。
LFU:Least Frequently Used,最不经常使用。
- 在一段时间内,数据被使用次数最少的,优先被淘汰。
14.Memcache和Redis的区别是什么?
(1)数据结构:Memcache仅能支持简单的K-V形式,Redis支持的数据更多
(2)多线程:Redis只使用单核,而Memcached可以使用多核,所以在比较上,平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis
(3)持久化:Redis支持持久化,Memcache不支持持久化
(4)分布式:Redis做主从结构,而Memcache服务器需要通过hash一致化来支撑主从结构
(5)存储方式:memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小. redis有部份存在硬盘上,这样能保证数据的持久性,支持数据的持久化(有快照和AOF日志两种持久化方式)
(6)内存使用率:对于key-value这样简单的数据储存,memcache的内存使用率更高。如果采用hash结构,redis的内存使用率会更高
(7)使用底层模型不同:新版本的redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
(8)过期策略:memcache过期后,不删除缓存,会导致下次取数据数据的问题,Redis有专门线程,清除缓存数据;
总结
两者进行对比,是因为都是内存数据管理系统,而实际上两者之间区别还是很大。
Redis更多的象一个键值对数据, 包括数据的持久化,主从架构,数据备份等策略都是为了保证数据安全以及高可用,
而Memcache更多的是一个数据缓存系统是为了提升数据的读取效率,所以两者的应用也有所不同,
Memcache适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等工作场合,
Redis除去做Nosql数据库使用外,还能用做消息队列,数据堆栈和数据缓存等。
15.怎么预估自己系统可承载的日活数?
16.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署?
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。 它可以用于测试静态和动态资源,例如静态文件、Java 小服务程序、CGI 脚本、Java 对象、数据库、FTP 服务器, 等等。JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能。另外,JMeter能够对应用程序做功能/回归测试,通过创建带有断言的脚本来验证你的程序返回了你期望的结果。为了最大限度的灵活性,JMeter允许使用正则表达式创建断言。
可以在多台机器上进行分布式部署
因为有时候单一计算机的JMter不足以模拟需要的压力测试,会导致JVM内存溢出等问题,所以需要多台计算机来协同模拟来完成测试
17.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求?
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(业务TPS = CAPS × 每个呼叫平均TPS)
TPS是软件测试结果的测量单位。一个事务是指一个客户机向服务器发送请求然后服务器做出反应的过程。客户机在发送请求时开始计时,收到服务器响应后结束计时,以此来计算使用的时间和完成的事务个数。
一般的,评价系统性能均以每秒钟完成的技术交易的数量来衡量。系统整体处理能力取决于处理能力最低模块的TPS值。
并发指的是同一时刻需要处理的请求,每秒并发数指的就是在一秒中有多少请求一块被执行
就是将所有的请求时间从小到大进行排序
例如有十个数1ms、2ms、3ms、4ms、5ms、6ms、7ms、8ms、9ms、10ms
那么90%线指的就是这个9ms有90%的时间都小于这个树
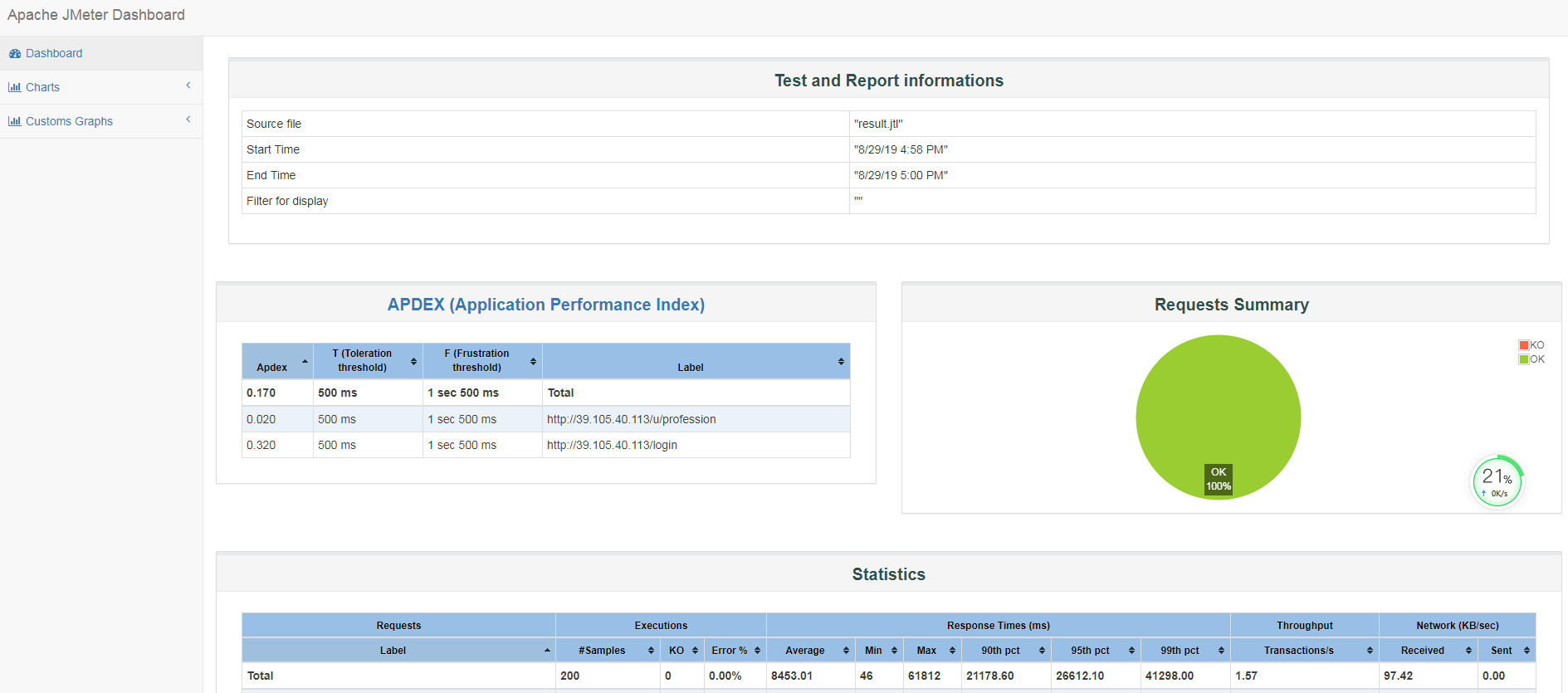
2、生成压测报告
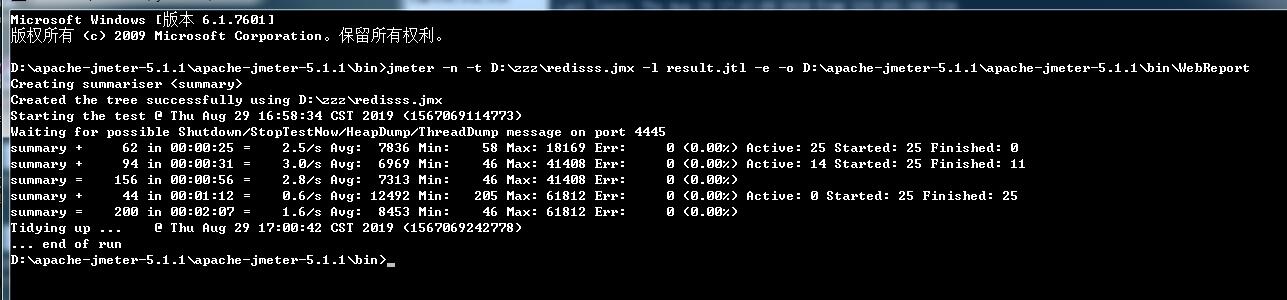
1、打开cmd命令模式进入Jmeter的bin目录。
2、输入jmeter -n -t D:\Jmeter\apache-jmeter-3.2\bin\test.jmx -l result.jtl -e -o D:\Jmeter\apache-jmeter-3.2\bin\WebReport
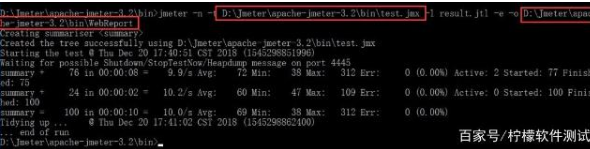
PS:红框部分的jmx路径地址以及生成的html测试报告路径地址必须要正确。
3、安装了两个谷歌插件
明天计划的事情:
开始任务7
尝试短信注册
遇到的问题:
无
收获:
以上




评论