发表于: 2019-08-29 17:06:55
1 713
今天学习的知识:
缓存击穿问题:
缓存击穿表示恶意用户模拟很多缓存不存在的数据,由于缓存中都没有,导致这些请求短时间都去访问数据库,使得数据库异常,这种情况,在有一些抢购活动,双十一。京东618啥的,秒杀活动的接口都被大量的用户恶意刷,导致数据库响应超时,好在现在数据库大豆读写分离,同时也有进行接口限流,能hold住。
解决方法一:
使用互斥锁排队
业界比较普遍的做法,根据key获取value的值为空时,锁上,从数据库中load 数据后再释放锁。若其他线程获取锁失败,等待一段时间后重试;这里注意一下,分布式环境要使用分布式锁,单机的话用普通锁(synchronized 、lock)就够了。
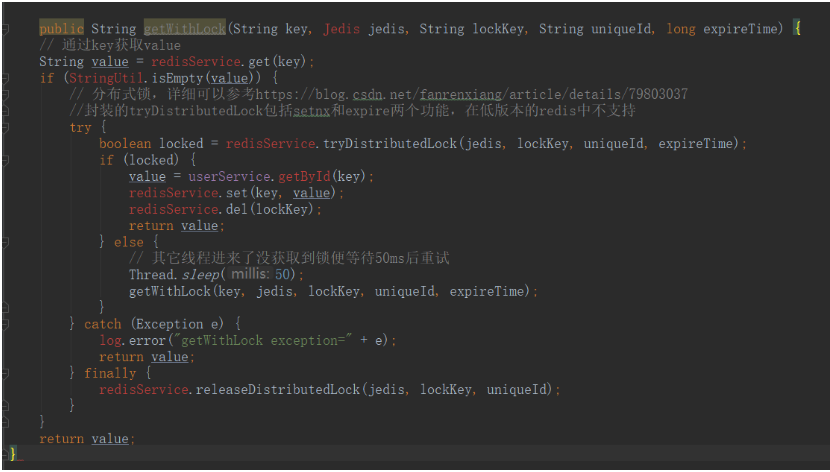
这样思路比较清晰,也从一定程度上减轻数据库的压力,但是锁机制使得逻辑的复杂度增加,吞吐量也降低了,有点治标不治本、
方案二:接口限流与熔断、降级
重要的接口一定要做好限流策略,防止用户恶意刷接口。同时要降级准备,当接口中某些服务不可用时,进行熔断、失败快速返回机制;
方案三:布隆过滤器
bloomfilter 就类似于一个hash set ,用于快速判断某个元素是否存于集合中,其典型的 场景就是快速的判断一个key是否存于某个容器中,不存在就直接返回。 布隆过滤器的关键在于hash算法跟容器大小,下面介绍简单的效果,这里用guava实现布隆过滤器:
缓存雪崩问题:
缓存在同一时间大量键过期(失效),接下来一大波请求瞬间都落在数据库中导致连接异常。
解决方案:
方案一:跟解决缓存击穿一样 加锁排队
方案二: 建立备份缓存,缓存A和B ,A设置超时时间限制,B不设置超时时间限制,先从A读缓存,A没有了去读B,并且设置更新A缓存和B缓存;
方案三: 设置缓存超时时间再家伙是那个一个随机的时间长度,比如缓存key 的超时时间是固定的5分钟家伙是那个随你及的2分钟,酱紫就可以一定程度上避免雪崩问题;

聚合报告的相关属性代表意义:
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
深度思考
1.后台只允许有列表页和详情页,列表页分为搜索区和列表区和操作区,原因是什么?有没有其他设计方式,相比之下各自的好处是什么? 点击查看相关小课堂
2.什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案? 点击查看相关小课堂
集群中每台服务器就叫做这个集群的一个“节点”,所有节点构成了一个集群。每个节点都提供相同的服务,那么这样系统的处理能力就相当于提升了好几倍(有几个节点就相当于提升了这么多倍)。
但问题是用户的请求究竟由哪个节点来处理呢?最好能够让此时此刻负载较小的节点来处理,这样使得每个节点的压力都比较平均。要实现这个功能,就需要在所有节点之前增加一个“调度者”的角色,用户的所有请求都先交给它,然后它根据当前所有节点的负载情况,决定将这个请求交给哪个节点处理。这个“调度者”有个牛逼了名字——负载均衡服务器。
集群结构的好处就是系统扩展非常容易。如果随着你们系统业务的发展,当前的系统又支撑不住了,那么给这个集群再增加节点就行了。但是,当你的业务发展到一定程度的时候,你会发现一个问题——无论怎么增加节点,貌似整个集群性能的提升效果并不明显了。这时候,你就需要使用微服务结构了。
某个时间段,访问量爆发或者这个时间段访问量很大的情况下
1.高可用集群,提升可用性
2.负载均衡集群,loadbalance 提升吞吐量
3.并行计算集群
4.并行计算集群
3.什么是压测,为什么要进行压力测试?JMETER工具的使用 点击查看相关小课堂
模仿真实环境。服务器能不能承受住访问,为软件上线做准备
Jmeter 下载安装
4.Memcache和Redis可否做集群?什么样的情况下应该做集群? 点击查看相关小课堂
Memcached 自身没有实现集群功能,可以借助第三方工具实现,如Memagent代理实现
Redis官方集群方案 Redis Cluster
Redis Cluster是一种服务器Sharding技术
大型促销活动,节假日有大量客户端访问的时候需要
5.什么是脏数据,缓存中是否可能产生脏数据,如果出现脏数据该怎么处理? 点击查看相关小课堂
脏数据:从目标中取出的数据已经过期、错误或者没有意义,这种数据就叫做脏数据。
脏读:读取出来脏数据就叫脏读。
1、主动更新:后台点击更新缓存按钮,从DB查找最新数据集合,删除原缓存数据,存储新数据到缓存(或者用定时任务来做)
问题:更新过程中删除掉缓存后刚好有业务在查询,那么这个时候返回的数据会是空,会影响用户体验,如果高并发穿透DB,可能导致服务器崩溃
2、由用户触发更新:前台获取数据时发现没有缓存数据就会去数据库同步数据到缓存
问题:当并发请求获取缓存数据不存在的时候,就会产生并发的查询数据的操作
3、提前加载好数据:后台点击更新缓存按钮,从DB查找最新数据集合,这里不删除缓存,通过遍历数据覆盖和删除掉无效的数据
6.插入,更新和查询数据的时候,读写缓存和DB的顺序应该是怎么样的? 点击查看相关小课堂
1.先删除缓存再更新数据库,产生脏数据几率比较大,比如两个并发操作,一个更新一个查询,更新操作删除缓存后,查到操作没有命中缓存,先把老数据读出来放到缓存中,然后更新操作更新了数据库,于是缓存中的数据还是旧数据们会一直是脏数据;
2.先更新后删除缓存(使用的场景比较多)
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据
7.JVM缓存和Memcache这种缓存的区别在哪里?是否可以不使用Memcache,只用虚拟机内存做缓存? 点击查看相关小课堂

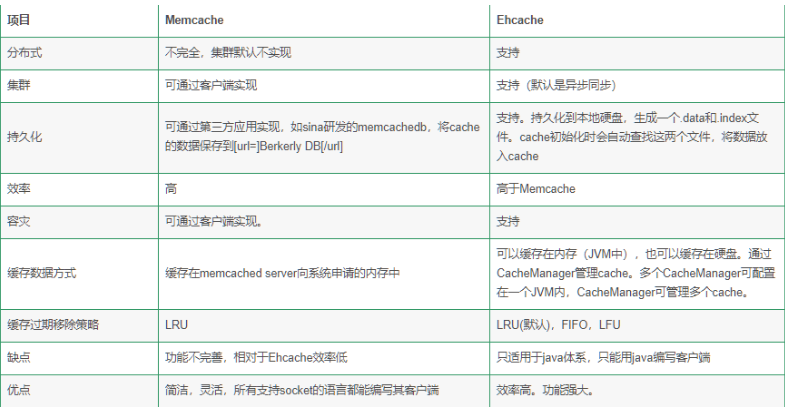
本地缓存
缺点:
1、 没有缓存大小的设置,无法限定缓存体的大小以及存储数据的限制(max size limit);
2、 没有缓存的失效策略(eviction policies);
3、 没有弱键引用,在内存占用吃紧的情况下,JVM是无法回收的(weak rererences keys);
4、 没有监控统计(statistics);
5、 持久性存储(persistent store);
集群内部,缓存的一致性如何保证?
如果采用ehcache的话,可以使用框架本身的JGroup来实现组内机器之间的缓存同步。
如果是采用google的cacheBuilder的话,需要自己实现缓存的同步。
A、非实时生效数据:数据的更新不会时时发生,应用启动的时候更新即可,然后定时程序定时去清理缓存;
B、需要实时生效数据:启动时可预热也可不预热,但是缓存数据变更后,集群之间需要同步
8.缓存应该在Service里,还是应该存放在Controller里,为什么? 点击查看相关小课堂
众说纷纭,网上都是各执己见,有的还说放在modle 层,但是好像说在 Service层的多一点
9.什么叫穿透DB?什么情况下会发生,穿透DB后会发生什么事情? 点击查看相关小课堂
准确说应该叫缓存穿透,高并发请求集体访问数据库,导致数据库负载剧增甚至崩溃
上面有写详细的
10.什么叫命中率?正常来讲,命中率应该控制在多少? 点击查看相关小课堂
缓存命中率:从缓存中读取到了数据,称为命中,没读取到需要从数据库中读取数据称为不命中,通常来讲,缓存命中率越高代表缓存使用的收益搞,应用的性能越好
影响命中率: 影响因素,缓存的大小,缓存的技术选型(内置本地缓存,分布式缓存),缓存框架的选择
如何监控缓存的命中率
在memcached中,运行state命令可以查看memcached服务的状态信息,其中cmd_get表示总的get次数,get_hits表示get的总命中次数,命中率 = get_hits/cmd_get。
redis中可以运行info命令查看redis服务的状态信息,其中keyspace_hits为总的命中中次数,keyspace_misses为总的miss次数,命中率=keyspace_hits/(keyspace_hits+keyspace_misses)。
11.什么样的数据适合存在缓存中?缓存的淘汰算法有哪些? 点击查看相关小课堂
- 静态数据,图片地址等。比如你有一个列表,数据都是从服务器获取的,会加载很多的图片和内容,而这些图片和数据并不会在短时间内就更新。那么建议采用缓存。这样除了用户在第一次打开会去请求服务器,后面都可以直接从缓存去获取,会大大加快加载速度。
- 页面跳转携带数据。通常用在跳转详情的场景。比如一个商品列表,点击某一个商品后需跳转到该商品的详情页。为了加快响应速度,并不需要每次跳转到详情页后再去请求对应商品的数据,而是在点击跳转时就将这个商品的数据存在缓存里,详情页直接获取缓存就行了。
- 全局都需要使用的数据。这里其实就和全局变量的作用很相似,至于怎样选择还看实际项目需要。
不需要写入缓存的情况
1、业务数据不常用(相对的),会导致命中率低,就没有必要写入缓存
2、如果写操作多,频繁需要写入数据库,也没有必要使用缓存;
3、数据量大,储存过大文件会给缓存带来很大压力。
golang算法
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据
12.什么叫一致性哈希,通常用来解决什么问题? 点击查看相关小课堂
一致性哈希分区
一致性哈希的目的就是为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash 后会顺时针找到临接的存储节点存放。而当有节点加入或退 时,仅影响该节点在Hash环上顺时针相邻的后续节点。
负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
13.缓存的失效策略有哪几种,分别适合什么场景? 点击查看相关小课堂
当缓存需要被清理时(比如空间占用已经接近临界值了),需要使用某种淘汰算法来决定清理掉哪些数据。常用的淘汰算法有下面几种:
FIFO:First In First Out,先进先出。判断被存储的时间,离目前最远的数据优先被淘汰。
LRU:Least Recently Used,最近最少使用。判断最近被使用的时间,目前最远的数据优先被淘汰。
LFU:Least Frequently Used,最不经常使用。在一段时间内,数据被使用次数最少的,优先被淘汰。
14.Memcache和Redis的区别是什么? 点击查看相关小课堂
前面日报有写
15.怎么预估自己系统可承载的日活数? 点击查看相关小课堂
建立日活的数学模型
影响日活的因素中,最本质的其实是两个,一个是每日新增用户数,一个是新增用户的留存率。
某一天的日活,我们可以看作是,当天的新增,加上前一天的新增的次日留存用户,再加上大前天的新增的二日留存用户……
以此类推,我们可以认为日活是“当天的新增用户和此前每一天新增用户在当天的留存用户之和”,基于此,我们可以用一个很简单的公式表达日活。
DAU(n)=A(n)+A(n-1)R(1)+A(n-2)R(2)+… …+A(1)R(n-1)
其中,DAU(n)为第n天的日活,A(n)为第n天的新增,R(n-1)为新增用户在第n-1天后的留存率。如果我们假设,每日用户的新增是一个固定的数值A,则公式可简写为:
DAU(n)=A(1+R(1)+R(2)+… …+R(n-1))
16.什么是JMeter?Jmeter是否可以在多台机器上分布式部署?为什么要分布式部署? 点击查看相关小课堂
在使用Jmeter进行性能测试时,如果并发数比较大(比如项目需要支持上万的并发量),单台PC的配置(CPU和内存)可能无法支持,这时可以使用Jmeter提供的分布式测试的功能。
根据目前PC的配置:4.00G内存,可以最多达到2000左右的并发数量。那么对于支持上万的并发量,一台PC是很难实现的。
Jmeter分布式执行原理
1 Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2 执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI,我理解它应该是通过命令行模式执行的。
3 执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
执行机(slave)配置
17.什么是TPS,什么是每秒并发数,什么是90%Line?分别应该到达多少算符合系统上线的要求? 点击查看相关小课堂
简单例子:在术语中解释了TPS是每秒事务数,但是事务时要靠虚拟用户做出来的,假如1个虚拟用户在1秒 内完成1笔事务,那么TPS明显就是1;如果某笔业务响应时间是1ms,那么1个用户在1秒内能完成1000笔事务,TPS就是1000了;如果某笔业务 响应时间是1s,那么1个用户在1秒内只能完成1笔事务,要想达到1000TPS,至少需要1000个用户;因此可以说1个用户可以产生 1000TPS,1000个用户也可以产生1000TPS,无非是看响应时间快慢。
TPS:Transactions Per Second(每秒传输的事物处理个数),即服务器每秒处理的事务数。TPS包括一条消息入和一条消息出,加上一次用户数据库访问。(
并发连接数指的是客户端向服务器发起请求,并建立了TCP连接。每秒钟服务器链接的总TCP数量,就是并发连接数。
聚合报告的相关属性代表意义:
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
#Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应时间
Median:中位数,也就是 50% 用户的响应时间
90% Line:90% 用户的响应时间
Note:关于 50% 和 90% 并发用户数的含义,请参考下文
http://www.cnblogs.com/jackei/archive/2006/11/11/557972.html
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec
在评定服务器的性能时,应该结合TPS和并发用户数,以TPS为主,并发用户数为辅来衡量系统的性能。如果必须要用并发用户数来衡量的 话,需要一个前提,那就是交易在多长时间内完成,因为在系统负载不高的情况下,将思考时间(思考时间的值等于交易响应时间)加到脚本中,并发用户数基本可 以增加一倍,因此用并发用户数来衡量系统的性能没太大的意义。
作者最后做了综述,他认为在性能测试时并不需要用上万的用户并发去进行测试,如果只需要保证系统处理业务时间足够快,几百个用户甚至几十个用户就可 以达到目的。据他了解,很多专家做过的性能测试项目基本都没有超过5000用户并发。因此对于大型系统、业务量非常高、硬件配置足够多的情况下,5000 用户并发就足够了;对于中小型系统,1000用户并发就足够了。
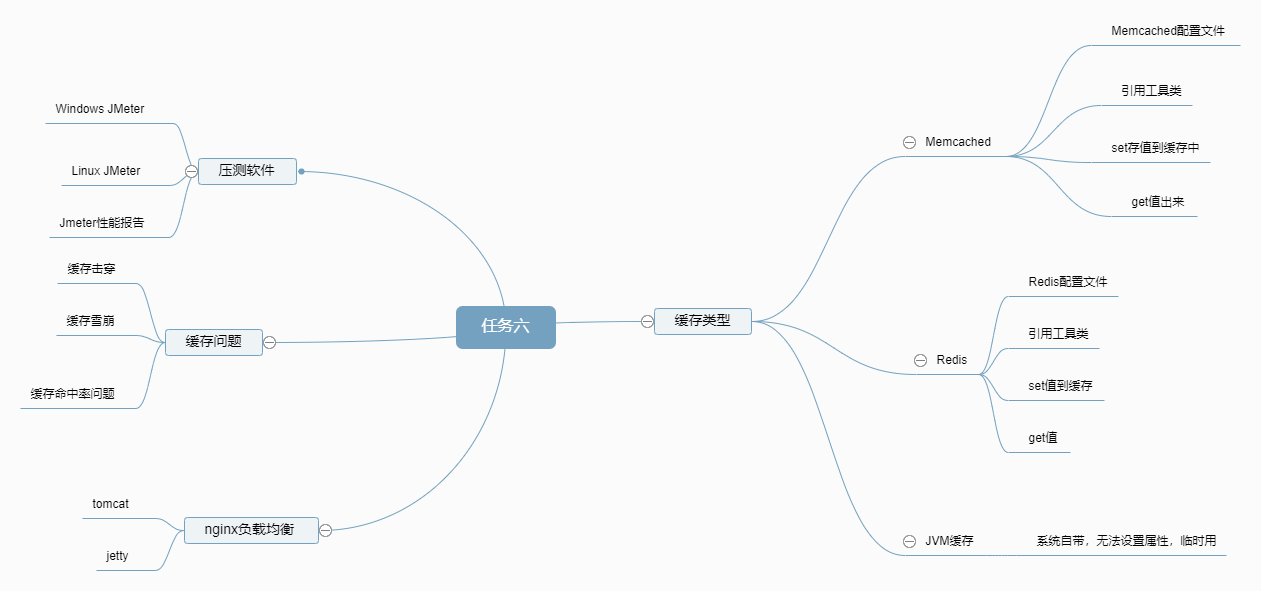
总结:
任务六我学到了缓存,缓存常见的类型,Memcached和redis,怎么去实现缓存,首先去找工具类,然后配置线程池,最后再需要的地方调用工具类实现set值跟get值,设置号缓存后需要模拟高并发场景,所以需要用到Jmeter来进行压测页面,就是模拟很多用户同时访问页面也就是高并发场景,本地测完继续再服务器测试,服务器也需要部署JMeter跟Memcached和Redis,




评论